Strong vs Eventual Consistency
This document examines the differences between strong and eventual consistency models in distributed systems. It discusses their definitions, use cases, trade-offs, and considerations for choosing the appropriate consistency model based on application requirements.
Definitions
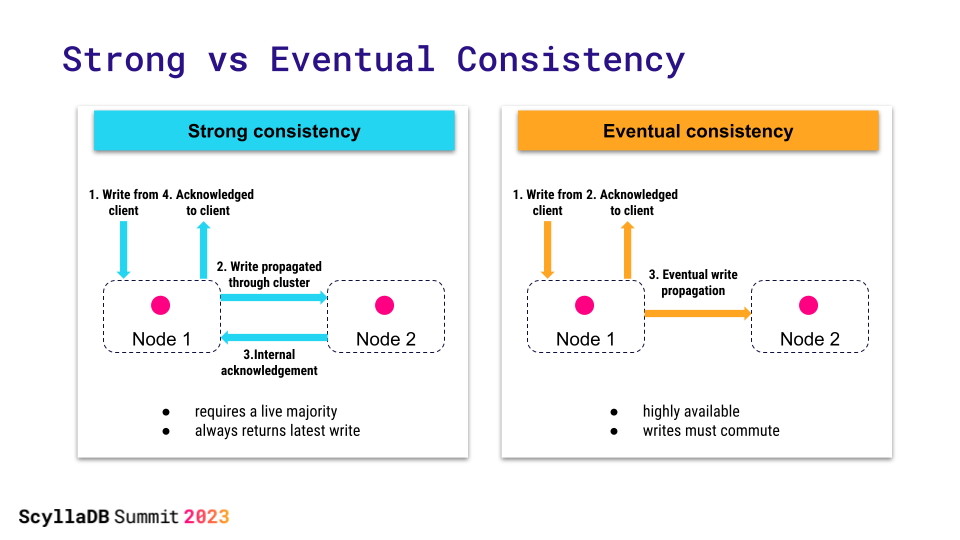
- Strong Consistency: In a strongly consistent system, once a write operation is completed, all subsequent read operations will reflect that write. This means that all nodes in the distributed system have the same view of the data at any given time. Strong consistency ensures that users always see the most up-to-date data.
- Eventual Consistency: In an eventually consistent system, updates to a data item will propagate to all nodes in the system over time. However, there may be a period during which different nodes have different views of the data. Eventually, all nodes will converge to the same state, but there is no guarantee of immediate consistency after a write operation.
Use Cases
- Strong Consistency: This model is suitable for applications where data integrity and accuracy are critical, such as banking systems, inventory management, and booking systems. In these scenarios, it is essential that users always see the most current data to avoid issues like double bookings or incorrect account balances.
- Eventual Consistency: This model is often used in applications that prioritize availability and scalability over immediate consistency, such as social media platforms, content delivery networks, and distributed caching systems. In these cases, temporary inconsistencies are acceptable as long as the system eventually converges to a consistent state.
Trade-offs Between Strong and Eventual Consistency
- Latency vs. Consistency: Strong consistency typically incurs higher latency due to the need for coordination among nodes to ensure that all have the latest data. Eventual consistency can offer lower latency since updates can be processed independently on different nodes.
- Availability: According to the CAP theorem, in the presence of network partitions, a system can only guarantee two out of three properties: Consistency, Availability, and Partition tolerance. Strongly consistent systems may sacrifice availability during partitions, while eventually consistent systems can remain available but may serve stale data.
- Complexity: Implementing strong consistency often requires more complex algorithms (e.g., consensus protocols) to ensure that all nodes agree on the current state of the data. Eventual consistency can be simpler to implement but may require additional mechanisms to handle conflicts and ensure convergence.
Considerations for Choosing a Consistency Model
- Application Requirements: Assess the specific needs of the application regarding data accuracy, user experience, and tolerance for stale data.
- Scalability Needs: Consider the expected scale of the system and whether the chosen consistency model can support that scale effectively.
- Network Conditions: Evaluate the likelihood of network partitions and how the system should behave in such scenarios.
- Conflict Resolution: For eventually consistent systems, plan for how to handle conflicts that may arise from concurrent updates.
Conclusion
Choosing between strong and eventual consistency models is a critical decision in the design of distributed systems. By understanding the definitions, use cases, trade-offs, and considerations associated with each model, system architects can make informed choices that align with application requirements and performance goals.
| « Amdahl’s Law | » Stateful vs Stateless Architecture |
| Back to Core Architecture Principles | Back to System Design Concepts |